Cheat Sheet (For the university kids)
- Distributed Architecture is the “bees knees” in web technology (scalability, dependency management & service management)
- Stateless communication is ideal for single page applications as view generation logic is completely separate from application data logic.
- Authentication is required on every request in stateless communication
- Identity can be shared between applications
- Users want to experience Single-Sign-On especially in enterprise
Why the why?!
This post will be exploring the required understanding to derive the why of what we will be building in the next few weeks. Without a “WHY”, even with a “WHAT” and “HOW” the learning becomes meaningless. Armed with a “WHY” I genuinely believe even without touching a piece of code, project managers, technical operations and even the everyday user can benefit from understanding the goal of this series.
Modern Software Architecture
In modern web-based technology, distributed architecture is key.
Distributed architecture has 3 key functions:
- Clearly defined dependencies
- Efficient scaling
- Re-usable components
No area does this hold more true for than in “Identity”. A user can be thought of as a persistent record (Or partial record) not only within a entire app but also across different apps. The question “Identity” aims to answer (to your app) is the same question your pubescent self once tried to answer:
WHO AM I?!
To explore how this can be answered we first need to understand the two basic forms of communication between server-client communication.
- Stateful
- Stateless
1. Stateful Communication
Stateful: The state of interaction is recorded therefore the context of communication can be derived not only from the information sent from client to server but also from previously established state.
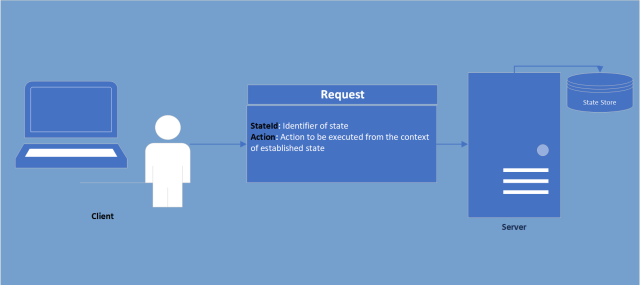
Why use stateful communication?
In some web-frameworks (Such as .NET MVC) UI rendering is done statically via generation of the source code (HTML, CSS & JavaScript) on server-side which is than sent to client-side. In the event of a partial re-render (Good example being filtering on a table) the server would require a understanding of what has previously been rendered to prevent unnecessary communication (Only sending to the client the new section not the entire page). This understanding or “State” is therefore stored on server and after establishment, all the client would need to do use this established state is send a reference.
As apart of this state-management you can also store the identity of the user and therefore handle security based on this state.
Why this is not my recommended approach.
- Stateful communication is managed differently in different technologies, therefore it makes multi-technology environments difficult to develop and maintain (I.e. web-app + iOS app)
- If identity is only maintained by client-server state, it makes it much more difficult (close to impossible) to create a smooth SSO experience
- Communication is much more complicated as to understand the communication you also need to understand the state stored on server (Complicating debugging and unit testing).
Time and place
At university most my courses was learning stateful communication based technology (.NET 4.5, JSP, JSF etc…) but upon learning about single page applications I could immediately understand the weaknesses of stateful communication. Without the requirement of server-side view generation, the benefits of stateful communication (admittedly there are some) do not outweigh the negatives. If you have a scenario where stateful communication is preferable (maybe a high-frequency polling web-application where the security verification overhead of communication would be too high in stateless communication) I am keen to discuss and please comment below.
2. Stateless Communication
Stateless: The state of interaction is not-recorded beyond the request. All required context must be derived from the request sent.

Why this is my recommended approach.
By never assuming state
- request management is clear and very well scoped
- following a request is as simply as sending the same request a second time
- communication can be framed in a well-known multi-technology format (Such as the RESTFul architecture)
Terms and conditions apply.
Just with almost everything in life there is a compromise in stateless communication. As there is no state, every request needs to be separately authorized and validated. This would not be ideal if we were doing server-side rendering (Imagine having to re-authorize every resorting of a table! The horror!). Thankfully this has been largely solved through modern UI SPA (Single page application such as Angular or React (To be continued in another post)) frameworks where client-server communication is separated between UI Logic and Application-data Logic, therefore only application-data requests would need to be authenticated (Much more tolerable).
Identity
Hopefully by now you agree (Or disagree but commented) as to why we will be using stateless communication. Without a state however how will you be able to identify yourself to the application? Very simply, we need to send with our request a identification token (Or cookie) to ensure that the application server will take our request appropriately.
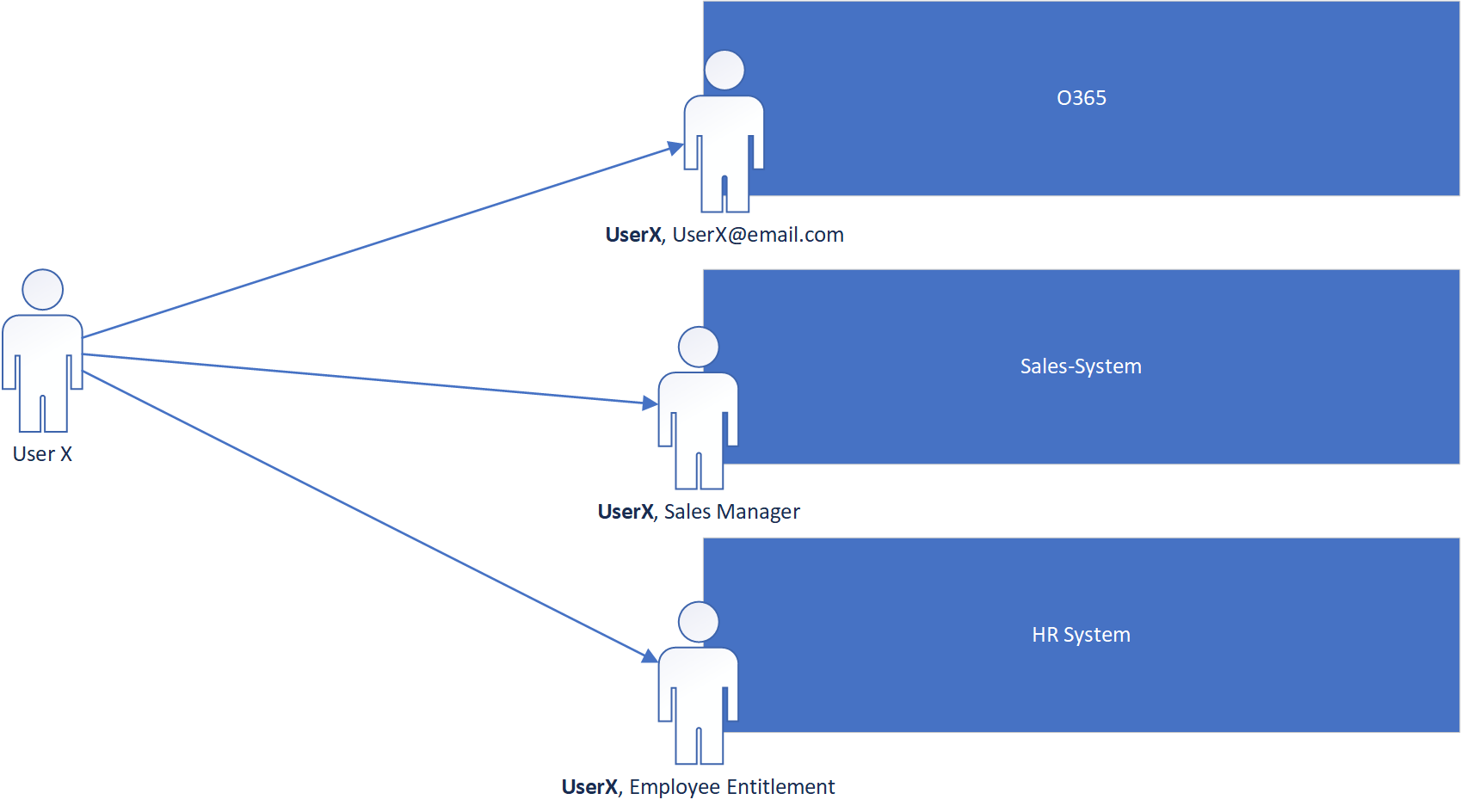
Simple enough? Now ask yourself… Why can’t we use that identification token between applications?! If my name is Tony on Facebook, why wouldn’t it be Tony on LinkedIn? The answer to this question is ABSOLUTELY we can use the same identification token, this rings true especially in Enterprise environments where your real identity matches your application identities.
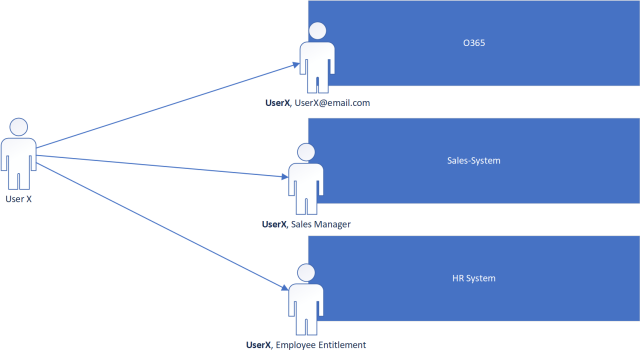
As depicted above, the “UserX” component of the application’s user identity is the same in every system therefore the UserX should be able to log into all 3 systems with the same identity. Each application than should be able to resolve the user independently and add on its own application specific Identity information (ie. Sales Manager, Employee Entitlement Id etc.).
Case and Point
This is the holy grail of UX. Ever use your google account to log into Dropbox? Or use Facebook to log into Instagram?! This is the “WHY” of this series. After this series, not only should you know how to authenticate your own Web-API with a existing identity provider (In this series we will explore OpenID Connect) but to build your own scalable “Identity Provider” ready to be used by ALL the applications you wish to share a Identity across.
Why we externalize the identity provider from our application is quite simple when looking at the diagram above. If we created a centralized identity based on another applications identity such as O365’s user identity (Which is possible), anytime O365 is taken offline, all your other applications would cease to be able to authenticate users (causing 100 help desks tickets and many upset users.) As such we separate the identity providing service as it is a super-dependency (Highest level dependency). There are product suites that do this separation for you.
The two I would recommend are AzureAD or Okta
AzureAD: https://docs.microsoft.com/en-us/azure/active-directory/active-directory-whatis
Okta: https://www.okta.com/products/it/
In this series though we will be building this ourselves using Identity Server 4, Docker, Reddis, PostGRE and more because even if in production you want to “pay to make it go away” I believe there is still a educational experience to be had and all technology I will be using is either free or has a free community version.
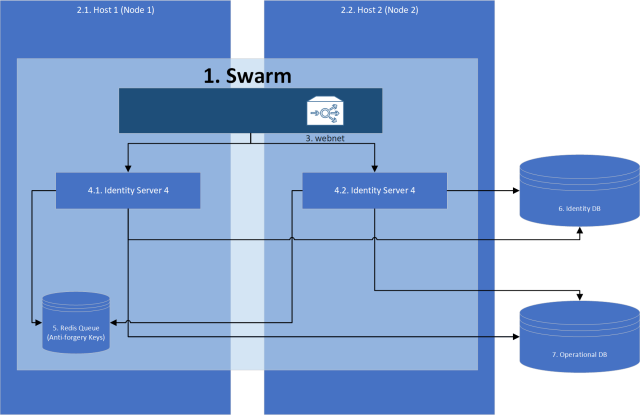
Bonus for getting to the end (Starting architecture we will be building ;)).